A talk: How To Find Things Online
This is a talk given at the Pervasive Media Studio for their lunchtime talks series. It is therefore written to be read. You can also watch the recording of the talk if you like - it takes the rough form of this post, but I think I landed a joke or two more than are on the page.
Hello, hi, I’m v buckenham, I’m an artist & game designer, and general person who uses the internet and thinks about the internet a lot. I make a lot of software tools that let people make other things, and I think a lot about how people interact online. As a plug for later, I’m currently making a game making tool called Downpour, which is super cool & you can playtest if you stick around for First Fridays later on.
But that’s not what I’m here to talk about today.
I’m here to talk about how to get the carrot cake from Otis in The Secret of Monkey Island.
So, it’s 1991 and you’re playing The Secret of Monkey Island. It’s a game about walking around and clicking on things and hearing funny dialogue and trying to solve puzzles by combining various objects. It’s a pretty cool game! It’s very funny. But the puzzles are… sometimes obtuse. So you’re stuck, and this is a time before you have an internet connection. So what do you do?
Well, if you were in the US, you might call a hint line! You ask for your parent’s permission (because it’s expensive), and you dial the special number, and then you either talk to a real person on the other end, or else you go through a little phone tree. And then it tells you to give him the gopher repellent to get past.

So this talk was billed about being about AI. I’m gonna get to that in a bit. But I’m using games as a framing device for this kind of history of how people could find out information as the internet has progressed. And how that information came to exist in the first place. Just keep that in mind that when I am talking about the gopher repellent, maybe I’m actually talking about, like, identifying a bird. And when I talk about the hint line, maybe I actually mean buying a strategy guide, an encylopedia, a telephone directory, talking to a librarian or putting an ad in the local paper.
So, in this example, we don’t yet have the internet. But information still exists! People know how to get past this puzzle. And if you didn’t know this information, if you couldn’t figure it out yourself, then what could you do? You could ask a friend. If you knew someone who knew this information, then they would probably tell you. And they would do this because people like to be helpful. If we wanted to get reductive about it it’s because providing small bits of assistance to other people is a way that people bond and form social relationships with each other. And forming social relationships is a thing that people love to do. It makes people feel good, and it means when they get stuck later on maybe you’d help. Reciprocity.
But maybe the person who knows how to get past doesn’t want to tell you, maybe this is a playground power games thing and they wanna keep this knowledge secret to exercise some power or because they think it’s funny to watch you struggle, or because you didn’t tell them how to beat a different game. Or you just don’t know anyone else with this game.
Well, then you could phone up the hint line or buy a guide to the game down in WH Smiths or write in to a magazine. And these ways will answer your question, and they will do so for a fundamentally economic reason. They want you to give them money, and in exchange they will provide a service to you. Even if the hint line was free, then it would be run by the games company, and they’d do that so that you’re more likely to buy their next game.
Okay! So. The Internet. Or “the World Wide Web”.
The founding of the Internet is a complicated story and honestly we don’t really need to get into it. Even the distinction between the web and the internet is kind of complicated. To summarise, let’s just say that people invented websites, and they were academics, and they were the kind of people that made logos like this

I think that’s beautiful. It’s that impulse from before, about the kid on the playground who tells you how to get past the puzzle. Why should they want to? Because they want to help, and they want to share what they know. And this urge online is a bit more abstract, it’s not just helping one specific person who you know and who you hang out with at lunch break. It’s helping… anyone. Without having to know who they are. They can ask their computer to make a HTTP request to your computer and your computer will automatically respond with a document, and then they can read this document, and answer their question. Gopher remover.
And like, this is not all there is to it. The people who made the internet did not do this purely out a love of humanity, although that was definitely a factor. They did it because they were academics, and being an academic means that you are paid to share knowledge. And you are rewarded for having your knowledge used. And since the invention of the Internet, people have invented things like “impact factors” and h-index scores, which measure how often other academics use your knowledge by which we mean cited your papers in their papers. Which of course is a similar thing that has become a totally different thing since we started measuring it and rewarding people for it.
But, anyway, the academics who invented the internet did not do it to share solutions for Monkey Island. But the good thing about the internet is that you can put whatever you like on there, and pretty soon the kinds of people who like games about saying clever insults to pirates got on there, and of course they were going to help each other get past puzzles.
So now it’s 1992, and you’re playing Monkey Island 2: LeChuck’s Revenge, and you got stuck on the waterfall puzzle. Then how would you get unstuck? Maybe you’d ask a friend who was also playing it, maybe in this hypothetical you are now at university and it’s someone who you’re in some student society with. But also, maybe you have the internet now, and so, pretty likely, you’d go onto GameFAQs and you’d look it up.

And GameFAQs is incredible. It’s this huge website, full of text files, and each text file was submitted by a particular person. Giving a walkthrough for a game, or for a section, or giving advice on strategy. I love it in part because each entry so clearly shows the hand of the person who made it. Like this one

which is a fully justified monospace document. Which seems kind of boring until you realise that in writing this, he had to choose words so that each line would have exactly the same length. And also describe how to speed run Super Metroid at the same time. Incredible.
And of course, I’m gonna turn to why he did this. Because he could. Because he wanted to show off. His name is on it, thousands of people have seen this and been impressed. And that’s why people wrote walkthroughs for GameFAQs. For status, to be helpful, to share their love of the game.
Now, where we are chronologically is up to the first big dot-com boom. And GameFAQs was founded by a guy called Jeff Veasey, who ran it for the first 4 years as a side project, a thing he ran as a hobby while working in tech. But it brought in some money - there was a sponsorship with IGN, a network of games sites, and after that ended there were banner ads that brought in some money. And it kept growing, and in 1999 it became his full time job.
Which… good for him! He’s performing a valuable service, and he’s getting paid to do it. Other people are doing the work of writing the walkthroughs, but he’s doing the work of keeping the servers on, doing moderation, upgrading the code, generally all the maintenance work that is needed to keep a machine constantly working. The internet is a place, but it is also a process, a set of responses that happen to particular signals, and he was keeping that going.
And now for the bit of the talk that is just a confusing barrage of corporate acquisitions. So, GameFAQs was bought by CNET in 2003. In 2007, Jeff Veasey left the site. CNET was bought by CBS in 2008. Nothing happened for a while. And then in 2019, CBS and Viacom merged to form ViacomCBS (which is now known as Paramount Global, and which owns Paramount Pictures). And then in December 2020 Red Ventures bought all the CNET properties from ViacomCBS, including GameFAQs. And then finally on October 3, 2022 Fandom acquired a bunch of websites from Red Ventures, including Metacritic, GameSpot, and of course GameFAQs.

And I should say that throughout all of this, GameFAQs has trundled on, less and less central in terms of videogame info, but keeping a committed core of users who liked to hang out in the message boards. Once a community gets going somewhere, people will hang on, making the space their own through all kinds of neglect and disuse. What are they supposed to do, go somewhere else and lose the community that has been a part of their lives for years?
Okay, so we’re up to last autumn, and… what do you know, there’s a new Monkey Island game!

Now, I should say that, in accordance with modern design sensibilities, the puzzles are less obtuse and there’s an in-game hint system. But nevertheless, let’s say you want to find out how to get past a bit of it. Where would you look today?
I can think of a few answers.
If you google it, you can find several websites that work in much the same way that GameFAQs did. Including our old friend IGN, which has survived through all these years.
For games websites, which are businesses, a large proportion of their traffic is stuff that comes through search. So, SEO, search engine optimisation, is important. Making sure you have the right keywords, trying to get backlinks, that’s a big thing. And just building out content that fits the stuff people are searching for. So most videogame news sites now have dedicated guides writers - people search for it, so they provide it. It’s basically the worst paid job of a badly paid industry, with the least focus on the writing quality/judgement.
And games websites are competing with companies like Fandom, who started out as “Wikicities”, set up by this guy:

And Fandom has a wiki for Monkey Island!
Fandom runs many many wikis for different properties. And they’re pretty garbage, by all accounts? It is hard to move a community at the best of times, and they actively resist moderators who attempt to move their communities away - taking over the wikis that are run there to remove any reference to the community moving. And they’re good at SEO, so they stay on the top page of the results. For video game communities like Super Mario, there is an ongoing tug of war between the community run wiki and the Fandom wiki.
And to look at why these sites exist - for Fandom, the company, it’s straightforward business. They gain money from the advertising on these pages, and they gain market value due to having higher traffic from many users. For people who actually write the wikis - they do it because they are in a community with other people, and they want to support that community. They want to share what they know, they want to support other people who are into the same weird thing they’re into.
Okay, so, other ways you might find out how to solve a puzzle in Monkey Island these days. Youtube! You can go onto YouTube and find a video walking through the whole game. You can find lots of videos of people playing games on YouTube. Did you know!
It’s pretty straightforward to understand why YouTube operates - they’re a crucial part of Google’s ad empire, which makes them a very large amount of money. Enough money they can pay the pretty considerable cost of storing and serving all those videos - I tried looking up how much storage space it takes up, and there’s no real consensus, but… exabytes? ie billions of gigabytes? multiple of those.
And people who put videos on YouTube, why do they do that? Well, it’s wanting to be helpful. And it’s a desire for fame, or at least recognition. It feels good to have “numbers”, by which I mean an indication that people have seen a thing you have done and an indication they approved. And YouTube pays money. Usually small amounts of money, but enough that I know people who make a living that way. And even if YouTube itself doesn’t give you enough money to live on, getting popular on YouTube, being known - that leads to other ways of making money, like a Patreon, or commercial sponsorships for videos. But really the money is less in providing a useful service, like putting out a video showing how to beat a game, and more in providing a simulacrum of that sense of community that people like. Viewers watch at home, by themselves, but they feel like they are with someone charming and friendly and it gives them a sense of being with a friend. The term for this is “parasocial relationships”, and it’s really where the money is in terms of making “content” online.
And the third way you might find out how to get past a puzzle in the new Monkey Island is… you’d ask someone. And nowadays if you want to find someone who has particular knowledge, you don’t have to hope to bump into them on the school playground, you can find them online. And so you can go to the Monkey Island Discord and you can ask someone for a hint
And again, why would they give you that hint. Well, it’s for the same reasons we’ve discussed. People want that sense of community, and Discord is the place to get it. Why contribute to a wiki that’s full of ads and annoying to use and makes a big company rich? Why buy a load of video gear and learn how to edit videos? If you wanna share what you know and in return receive a sense of community, it’s best to do that in a small space that’s hard for someone to insert capitalism into. Where you can form actual two way relationships.
And of course Discord is still a corporation and has it’s own incentives - news announced this week of how they were changing usernames has been generally taken as a sign that they are moving towards being a more open platform where communities will be a bit more exposed to the light.
But this is a shift you can see across more than just games communities. In the world of social media, there is a general shift away from public-focused platforms like Twitter and Instagram and towards smaller communities built on mutual trust. In many ways I think this is a shame - there’s a lot of power in having information somewhere where anyone can see it, where what you know isn’t predicated on who you know. When it comes to information about how to get work, how to access things important for people’s lives, making connections…
Okay! So that was last year. And now finally!! Let’s talk about AI. We’re in the future now!!!
So, you might have heard, but in the last decade or so, AI has been having a real resurgence. The computers have gotten big enough for neural net techniques to be applied on a large scale. And the Internet has provided the vast quantities of data that they need to be trained on. There’s a bunch of different models out there, but I’m gonna focus on a type called “Large Language Models”.
How do they work? Well, GPT works something like this:

These are basically a machine that is trained to guess the next letter in a sequence of letters. If given the sequence of letters H-E-L-L it’ll probably guess “O”. Or maybe a space. And the way you train them is that you give them some text, and you look at what it thinks is likely to come next, and you tweak the machine to make the thing that actually does come next very slightly more likely. And you keep doing this, repeatedly, with all the text you can find, until it is very good at it.
2048 letters of input, 800 gigabytes of connections (“hidden layers”), and one letter of output. It’s honestly not that important how that middle bit works for our purposes - just connections with various strengths that end up producing the right answer, and that, if they give the wrong answer, the people training it can tweak them until they do produce the right answer.
And of course computer scientists have sweated over it a lot. How to structure that middle bit, how to turn “letters” into “math”, how to tweak the structure to train it, how to structure the training data, how to make the whole thing run just about fast enough & just about cheaply enough to be practical. And the interesting thing about a lot of these answers is that often the decisions are based on trying things and seeing how well they work rather than any kind of, like, really solid theory on why a particular thing is a good idea.
And of course, once you’ve trained it, no-one knows where the information inside it is. It’s just… 800 gigabytes of “model”, there’s no part of it you can point to and say “here’s where it contains the word hello”.
Anyway, that’s the machine, it’s a thing that guesses the next letter. And the thing about having a machine that is really good at guessing the next letter is that you can run it repeatedly to produce longer and longer strings of text. And if it’s really good at guessing the next letter, then those strings of text will look like text that people have written. So if you start a bit of text with “If a pirate says “I got this scar on my face during a mighty struggle!”, the correct reply is” then it might know that could continue with something like “I hope now you’ve learned to stop picking your nose.”. Somewhere in that big letter-guessing machine it encoded information about Monkey Island! We dunno where or how, but it needed to learn that to get good at guessing the next letter, so it did. I think it’s important to break this down a little like this, because so often people use the words “think” or “know” or “understand” and they’re useful shorthands, but they’re also kind of misleading when trying to understand what’s actually happening. The same as whenever someone says that evolution “likes” or “wants” something. There’s no desire here, there’s just… fitting better to the task.
But at the same time, it’s pretty extraordinary how effective this machine, that is just trained to predict the next letter, how good it is at a whole range of things. Like, we’ve talked a bit about how it might tell you the right answer for an insult swordfighting puzzle, but it has internalised a lot more stuff than that. I asked one about me, and it knew some facts, which is kind of wild to me. And it’s not just regurgitating facts - it can obviously generate stories, poems, copy, text of all kinds. And you can also ask it to write code for you - it has digested enough code and enough tutorials that it can generate explanations of what’s going on with it or write new code given questions about what’s needed (assuming, in my experience, if it’s seen code like that before). And you can get even more out of it by asking it to talk to itself, explain what it’s doing to itself - that gives it a short term memory, and allows it to start planning things. Or if you tell it a format for interacting with the world - it will do those things, and use the information it gets back as prompts to write more.
But again. It doesn’t think. It doesn’t learn. It doesn’t have a memory. It’s just fundamentally the probability of the next letter.
(And if you’re wondering what the difference is between GPT and ChatGPT, it’s that ChatGPT has been finetuned (trained a bit more) to be better at completing text that’s shaped a bit more like a dialogue. People aren’t used to asking questions of a machine by writing the first bit of the answer and then waiting for the machine to fill in the rest of it - they prefer just asking the question and getting a response.)
Anyway. For all this to work, we need to train the AI on a lot of text. The more text it sees, the better it gets at picking the next letter. So the companies that make these, like OpenAI and Google and Facebook, they feed it all the text they can get their hands on.
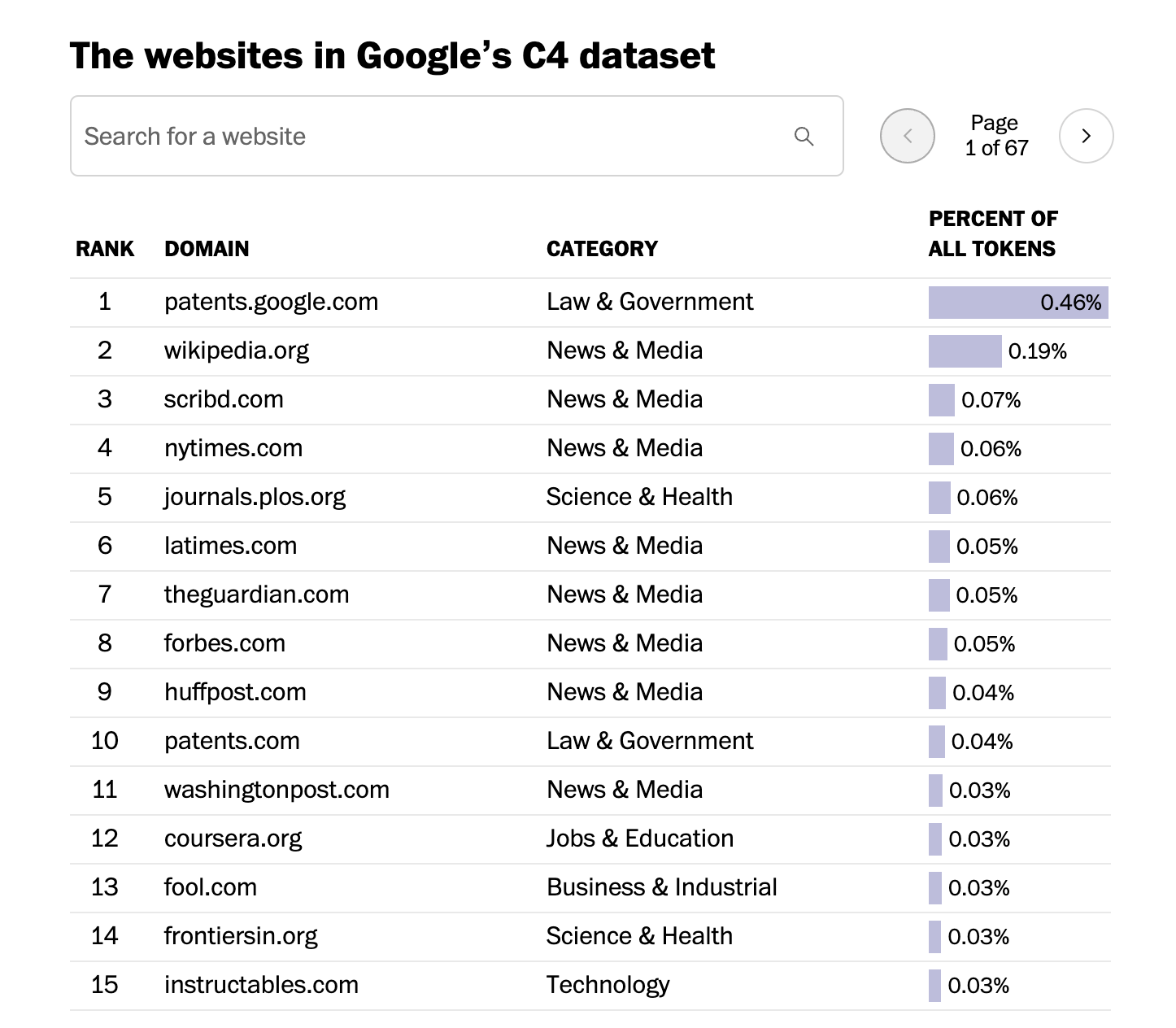
Which in this case means… pretty much everything I’ve discussed so far this talk. GameFAQs is in there, all the wikis are in there,

So we can see, like 3.8 million words from GameFAQs in one common training set.
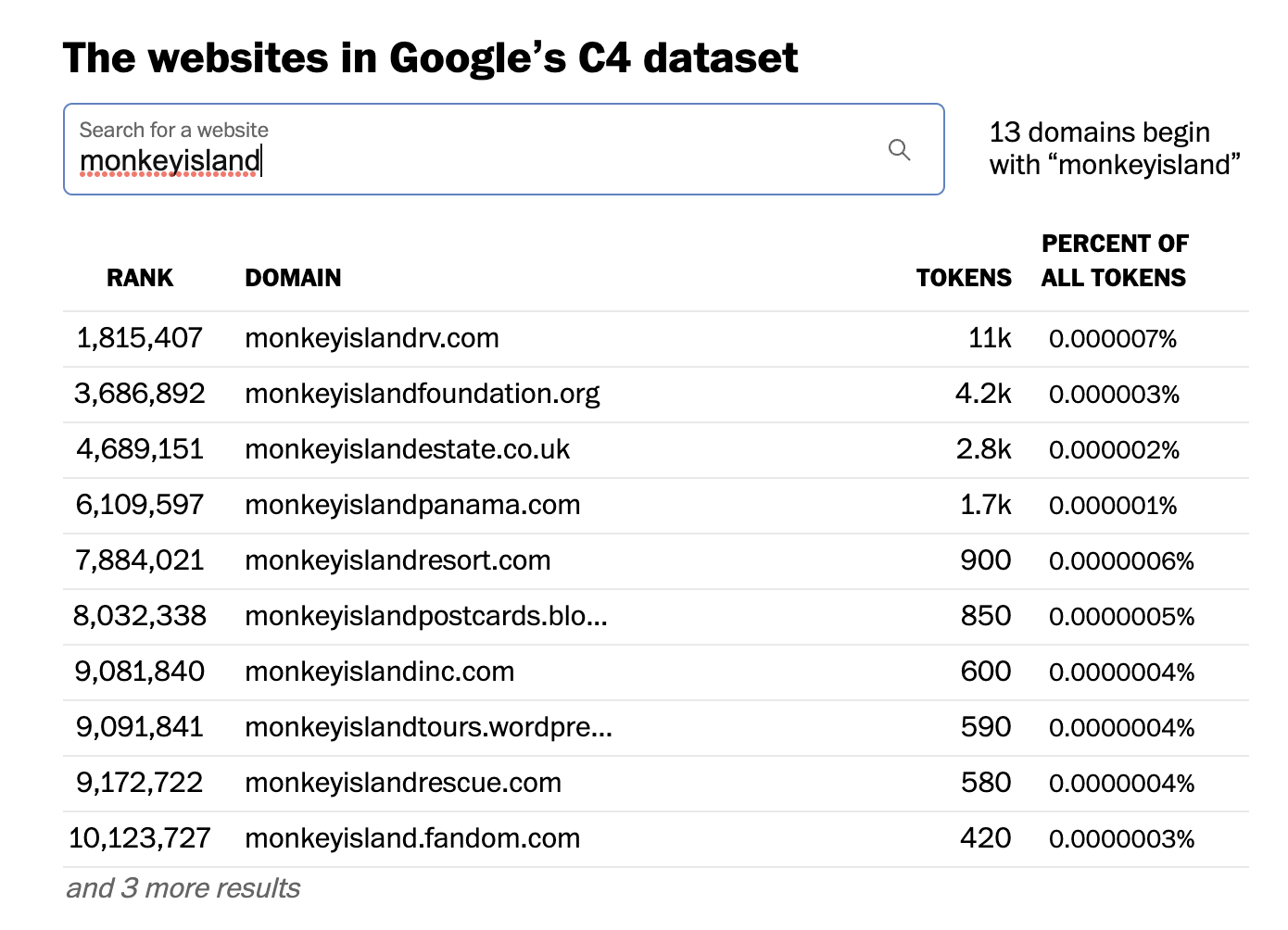
And 420 words from the Fandom Monkey Island wiki.
So. To return to our Monkey Island example, when the next game comes out (and I should note that as far as I’m aware, they’re not planning on making another one), and we get stuck, and we decide to ask the computer how to get past the puzzle. And we type the question into a next generation search engine that is actually just a large language model. What answer do we get? And where does it come from?
Well, maybe it’ll be helpful. Or maybe… it’ll just hallucinate something. And at this point in writing the talk, I tried to prompt ChatGPT to make some nonsense for me, and
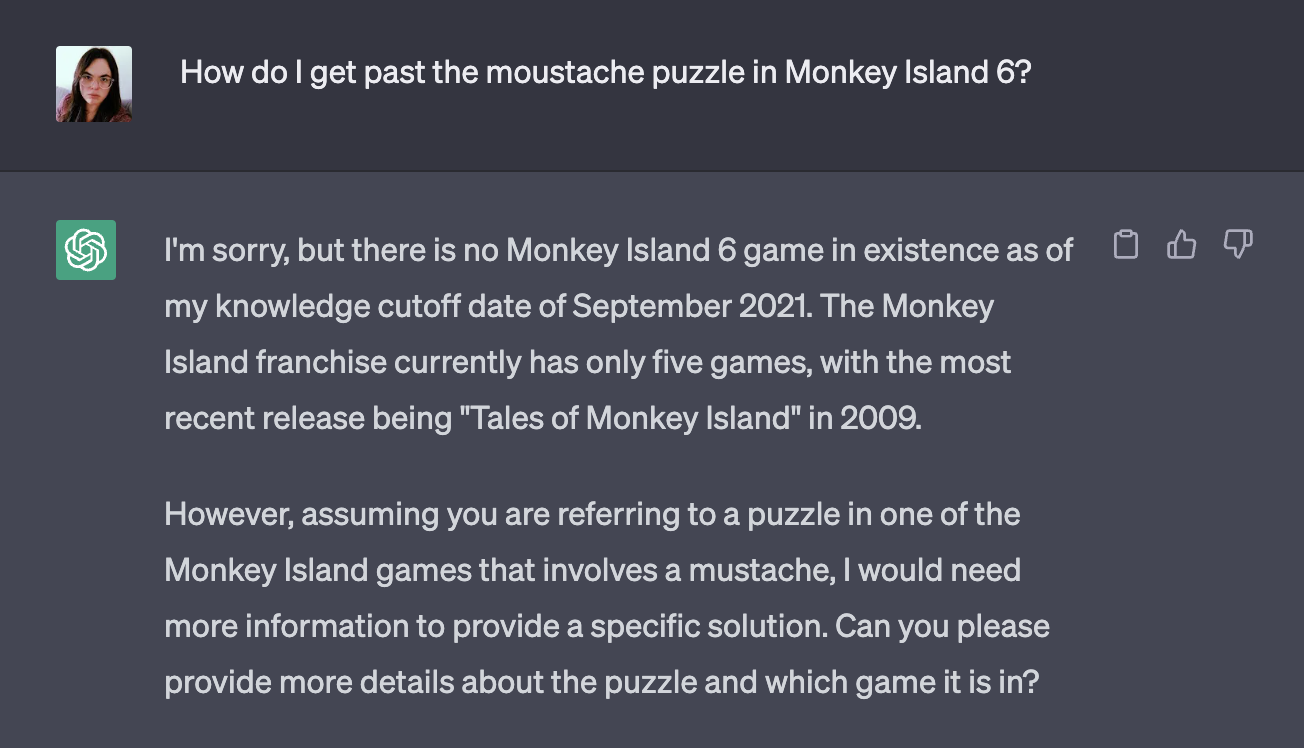
It didn’t fall for it. Annoying.
But then I tried the puzzle from before
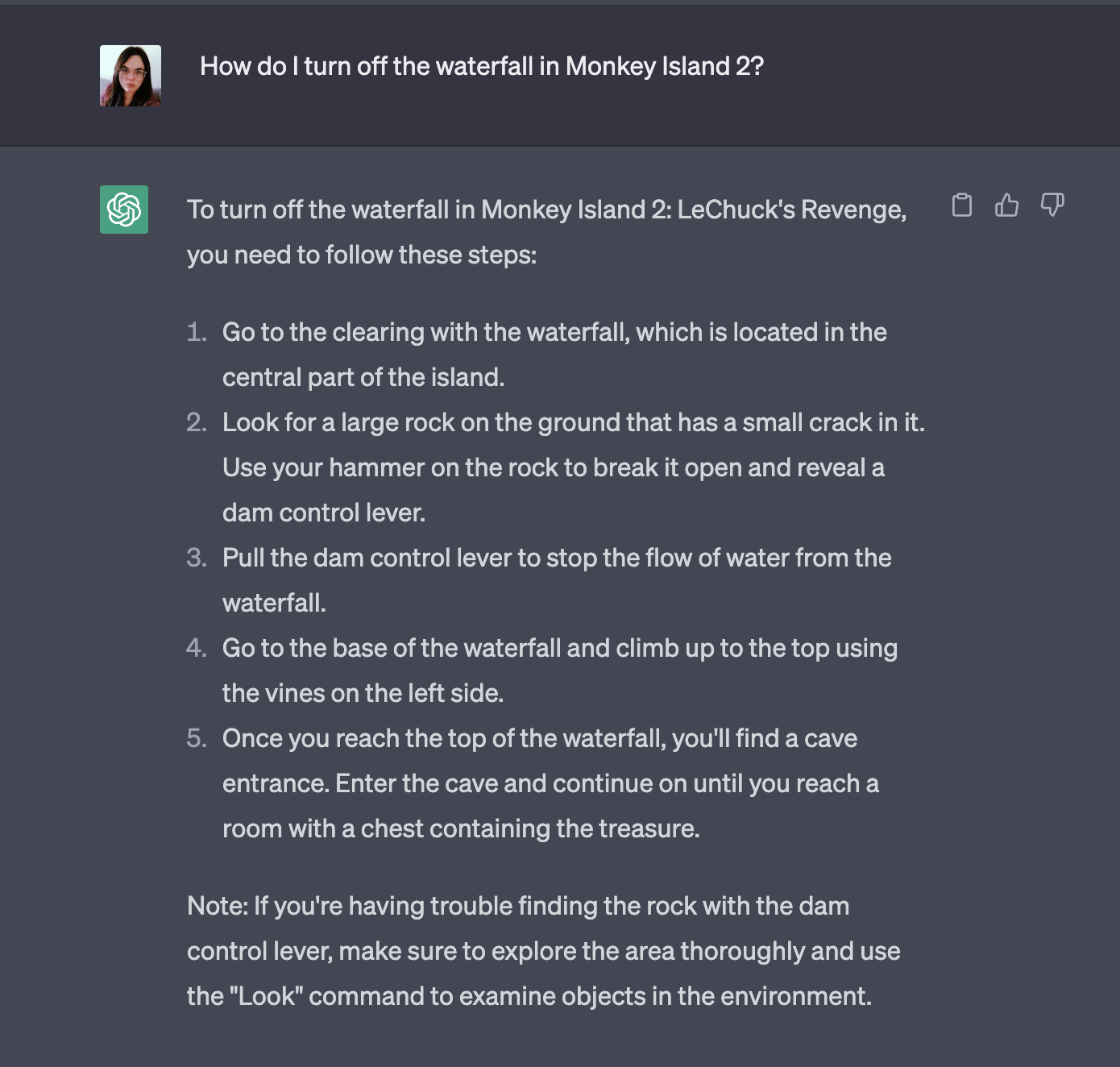
and it happily made something up for me.
So yeah, this is actually pretty reasonable as an outcome, it “knows” what an adventure game is, and it “knows” what kind of format the answer would come in, but the actual answer is not encoded in those 800 gigabytes.
But we’re setting this hypothetical in the future, not in the present. And maybe the model has gotten better. Bigger, more reliable. And, if it has read the answer somewhere online, then it can actually pick up the answer. Or maybe it has been fused with a traditional search engine, so it can look things up itself, “understand” what it reads and then return the answer to you. This is a technique many of the search engines are actually using these days, which helps with the bullshit problem, and also means it can answer questions that relate to stuff that’s happened since the model was trained.
But here’s where I think things get a bit screwy - the question then becomes… why does someone write the walkthrough and publish it online? There’s already this shift from publishing information openly and without expecting reciprocity. And towards either a really corporate model, where you’re really trying to extract money from it. Or towards a much smaller group, where you’re talking within small groups of trusted friends. And neither of these groups has much incentive to write up stuff that can train AI models.
For the groups of friends on Discord, or even studios running community groups… these communities exist because they are in relative privacy. They don’t want their chats to be public - in a search engine or inside a large language model. And there’s a tension here where the AI companies would love to get their hands on this data, all this rich data about how people actually talk that would make their robots work so much better. So I think there’s an open question about how well the companies that provide these platforms, like Discord, will shield their users from this kind of disclosure. And there’s encouraging trends here, in terms of smaller group chats, like Signal and WhatsApp moving towards end to end encryption by default. And you can see greater awareness of data rights & the harms that can come from indexing on social networks like Mastodon. Obviously that’s a little skewed because it’s full of nerds (and full disclosure, so I am), but I think it shows the way that people are increasingly aware of this.
But of course, the flipside to this is that we lose much of the sense of the “commons” that has characterised the Internet so far. You lose a lot of the serendipity that comes from logging on and suddenly talking to someone in another country, who maybe shares an interest in adventure games with you but is otherwise quite different. And once people are in smaller groups, then in-group norms can shift and become more accentuated from each other. If these are norms that seem kind of harmless then this is called a filter bubble and journalists wring their hands in The Atlantic about how it’s happening to them. And if these are norms that seem kind of racialised or scary then it’s called radicalisation, and journalists wring their hands in The Atlantic about how it’s happening to other people.
Anyway, that’s one motivation for writing this information up somewhere where the AI can read it gone. What about the other main motivation, profit?
For the companies like Fandom or IGN, they make their money from advertising to people who visit their websites. And, like, to state the obvious, but if a robot tells you the answer then you don’t have to visit the website. It is generally a pretty terrible time right now to be working for a website that tries to make it’s money from selling advertising space next to well written articles. I mean, not that it has been a good time for a good while now. But while people talk a lot about the threat caused by robots writing the articles, I can’t help but think that the problem of robots reading them is worse. And the kind of friction you might imagine between the AI models & the sites they’re being trained on is already starting to happen. Reddit, for example, has tried to stop AI models from training on their data (at least, without paying them).
But there are other business models out there. Remember, way back when we were using the telephone to find out answers? Those lines were often run by the companies who made the games. So there’s still a reason for the people who make products to make websites. Even if people don’t read it, you start writing for the robots. And you see this already, don’t you, the little grey text at the bottom of the shopping page that is clearly written not for people to read but for Google’s crawlers? Well, no doubt the same thing is going to happen by for telling Large Language Models specific facts about the world you want them to internalise. Is it unethical to publish a lot of fake reviews for your product if you never meant any human to look at them? Is it unethical if they’re fake negative reviews for your competitors? And people are doing this today, in little jokes, like:
While playing around with hooking up GPT-4 to the Internet, I asked it about myself… and had an absolute WTF moment before realizing that I wrote a very special secret message to Bing when Sydney came out and then forgot all about it. Indirect prompt injection is gonna be WILD pic.twitter.com/5Rh1RdMdcV
— Arvind Narayanan (@random_walker) March 18, 2023
And there are measures the new search engines can take to try to prevent this - this text was fully invisible, but that SEO spam text has to be visibile to be picked up on. But ultimately it’s an arms race between the spammers and the people running the LLMs, and I think on this one the LLM people have a bit of a disadvantage - because they don’t know how their machines work, and have to discover things about them experimentally, just the same as the spammers.
And I guess this is my overwhelming message here - that the crucial thing with AI is the data it’s trained on, and the crucial thing for that is the reasons people create it, and the way that it exists in a wider ecosystem. I’m pretty down on AI in this talk, and fundamentally that’s because I don’t see how these new AI interfaces loop back round and motivate the publication of more training data. By which I mean, people sharing what they know for other people.
And maybe AI will solve this, maybe we’ll have AIs that play the games themselves and generate walkthroughs, and AIs that read scientific papers and write accurate press releases for other AIs to digest. But without the kinds of feedback mechanisms that come from having people reading other people’s work, it’s pretty easy to see how that could become pretty weird pretty quickly. Or maybe we’ll get stuck in this kind of 2023-era, where the weird turns of phrases we use now get locked in forever, as later training sets start getting filled up with AI generated text that recreates the phrases we use now.
And the other way to look at this, really, is not about AI at all, but seeing this as the continuation of a gradual corporate incursion into the early spirit of sharing that characterised the internet. I say incursion but maybe the better word is enclosure, as in enclosure of the commons. And this positions AI as just a new method by which companies try to extract value from the things people share freely, and capture that value for themselves. And maybe the way back from this is being more intentional about building our communities in ways where the communities own them. GameFAQs was created to collate some useful stuff together for a community, and it ended up as part of a complicated chain of corporate mergers and acquisitions. But other communities experienced the kinds of upheaval that came with that, and then decided to create their own sites which can endure outside of that - I’m thinking here especially of Archive of Our Own, the biggest repository for fan-writing online. And incidentally, the source of 8.2 million words in that AI training set, larger even than Reddit.
And there’s a lot more to talk about with AI, and the weird things going on in that space. Even just with LLMs, there’s stuff about fine tuning for different tasks, the explosion of open source models, prompt injection attacks and how impossible they seem to be to mitigate… And outside LLMs there are obviously models that make pictures, understand video, do all kinds of different things. But I still I always return to the same question with AI - where does the training data come from? And, if this AI thing catches on, where will it come from, in the future?
Some more reading:
“in 2003 I could have googled this and gotten to a neon blue geocities called Jim’s Teeth DYI”
“Where do we go when good web citizenship itself may be biting people?”
“But if even trusted sources start mixing in just a lil bit then there no incentive not to.”
“Nobody was told this was happening; many fic writers still don’t know that their work was scraped at all.” (added 13 June)
11 May 2023